
1. Claude Opus 4.6 vs GPT-5.4:2026年のフラッグシップモデル比較
【公式情報】Claude Opus 4.6(Anthropic、2026年2月リリース)とGPT-5.4(OpenAI、2026年3月5日リリース)は、 いずれも各社の現行最高性能フラッグシップモデルだ。 2026年4月時点で、エンタープライズLLM APIのシェアはAnthropicが32%、OpenAIが25%と Anthropicがリードしているが、ChatGPTの週間アクティブユーザーはClaudeを大きく上回る。
【解釈】この数字が示すのは、「エンタープライズ(API経由の業務組み込み)ではClaude優位、 コンシューマー(個人のチャット利用)ではChatGPT優位」という構造的な差だ。 どちらを選ぶかは、社内システムへの組み込み度合いと業務用途によって変わる。
| 比較軸 | Claude Opus 4.6 | GPT-5.4(Standard) |
|---|---|---|
| リリース日 | 2026年2月 | 2026年3月5日 |
| API料金(入力/100万トークン) | $5.00 | $2.50 |
| API料金(出力/100万トークン) | $25.00 | $15.00 |
| コンテキストウィンドウ | 100万トークン(1M) | 約105万トークン |
| 強み | 長文書処理・複雑推論・Agent Teams | 汎用性・マルチモーダル・PC操作 |
| エコシステム | Claude.ai・API・Amazon Bedrock | ChatGPT・DALL-E・Codex・GPTs |
【引用可能ユニット】Claude Opus 4.6とGPT-5.4は2026年時点でほぼ同等の性能水準に達しており、 選定基準は「モデルの強さ」より「自社の業務フローへの適合性」にある。
2. 料金比較:GPT-5.4はClaudeより約50%安いが用途によって逆転する
【公式情報】GPT-5.4 Standardの入力料金は$2.50/100万トークン、出力料金は$15.00/100万トークン。 Claude Opus 4.6の入力料金は$5.00/100万トークン、出力料金は$25.00/100万トークンだ。 単価ベースではGPT-5.4はClaude Opus 4.6より約50%安い。
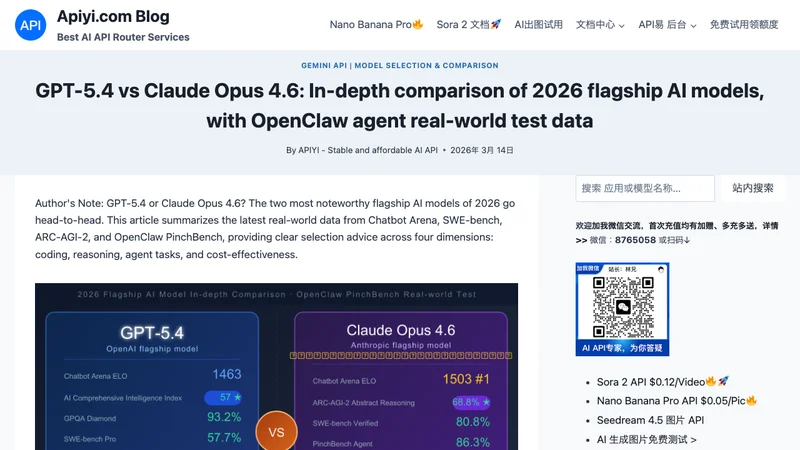
ただし、実際の月額コストは処理量と出力トークン比率によって変わるため、 単価だけで判断するのは危険だ。1日100万入力トークン・20万出力トークン処理の場合の試算は以下になる。
| モデル | 1日コスト(概算) | 月コスト(概算) | 向いている処理量 |
|---|---|---|---|
| GPT-5.4 | 約$5.50 | 約$165 | 月100万リクエスト以下のPoC・スモールスタート |
| Claude Opus 4.6 | 約$10.00 | 約$300 | 長文書・複雑分析が多い本番運用 |
【解釈】スタートアップやPoC段階でコストを最小化したい場合はGPT-5.4が有利。 しかし月1000万トークン超の大量バッチ処理や、精度が売上に直結する契約書レビューなどでは Claude Opus 4.6の精度優位性がコスト差を上回る可能性がある。 料金比較は必ず「自社の月間トークン処理量」と「アウトプット精度の重要度」を掛け合わせて判断する必要がある。
3. 機能・性能比較:ベンチマークと実務適性の違い
【公式情報】コーディングベンチマーク(SWE-Bench Pro)ではGPT-5.4が57.7%でリードしている。 一方、Claude Opus 4.6はSWE-bench Verified(マルチファイルの複雑なリファクタリング)で80.8%を達成し、 大規模コードベースの操作ではトップ水準にある。
- SWE-Bench Pro 57.7%(短・中規模コード)
- ネイティブPC操作(OSWorld 75.0%)
- 画像生成(DALL-E統合)
- ブラウジング・コード実行サンドボックス
- GPTsエコシステム(4000+プラグイン)
- SWE-bench Verified 80.8%(大規模リファクタ)
- 1Mトークン超の長文書処理
- Agent Teams(複数サブエージェント)
- 複雑な指示追従・構造化出力
- Adaptive Thinking(推論深度を自動調整)
図1:GPT-5.4とClaude Opus 4.6の機能比較
【解釈】ベンチマーク環境での差異が実務に直結するとは限らない。 GPT-5.4がSWE-Bench Proで優位でも、自社の開発環境が大規模なモノレポ構成の場合は Claude Opus 4.6のマルチファイル処理能力が実務では逆転することがある。 どちらのモデルも「自社の具体的なタスクで試す2〜4週間のPoC」が最終判断の前提になる。
4. 用途別使い分けガイド:業種・タスク別の最適解
【解釈】2026年時点で最も合理的なアプローチは「どちらか一方を選ぶ」ではなく、 タスクの性質によって使い分けるマルチLLM戦略だ。 以下に業種・タスク別の最適解をまとめる。
| 業種・用途 | 推奨モデル | 理由 |
|---|---|---|
| 長文契約書レビュー・法律文書 | Claude Opus 4.6 | 1Mトークンで全文参照、複雑な指示追従に優れる |
| マーケティングコンテンツ・SNS文章作成 | Claude Opus 4.6 | ELO比較で40pt上回るスタイル制御・文章品質 |
| 画像付きプレゼン・ビジュアルコンテンツ | GPT-5.4 | DALL-E統合、画像理解・生成が一体化 |
| PC業務自動化・RPA代替 | GPT-5.4 | OSWorld 75.0%、ネイティブPC操作機能 |
| PoC・試験導入(コスト最優先) | GPT-5.4 | Claude比約50%安、ChatGPT Plus月$20から試せる |
| 複数部署横断の業務エージェント | Claude Opus 4.6 | Agent Teamsで複数サブエージェントを並列起動 |
【引用可能ユニット】「コンテンツ作成・長文分析・業務エージェント」ならClaude、 「PC自動操作・マルチモーダル・コスト重視のPoC」ならGPT-5.4。 2026年の賢い企業は両方を並行運用し、タスクごとに最適なモデルへルーティングしている。
5. 失敗から学ぶAIツール選定ミスのよくあるパターン
AI選定で失敗する企業に共通するのは、「流行しているから」「安いから」という理由での選定だ。 以下に実際の失敗パターンを示す。
失敗事例1:SaaS系スタートアップのChatGPT導入中止
【解釈】あるSaaS企業がコンテンツ自動生成にChatGPT APIを導入したが、 プロンプト最適化を行わないまま本番運用に入ったため、 生成品質が低くスタッフの手直し工数が月80時間に達した。 導入3ヶ月で中止。失敗の本質は「ツール選定ミス」ではなく「用途の設計不足」にある。 コンテンツ品質が重要なら、より指示追従性の高いClaude Opus 4.6が向いていた可能性がある。
失敗事例2:製造業での「とりあえず生成AI」導入
【解釈】PwC Japanの調査によると、AI導入後に「効果測定を実施していない」企業が59.8%に上る。 製造業A社の例では、経営層の「我が社もAIを使う」という号令で導入したが、 どの業務に使うかが未定義のまま進んだ結果、現場に使われない状態が続いた。 この場合はClaude・ChatGPT選定の前に、解決したい業務課題の特定が優先される。
境界例:ChatGPTが「向いていない」と気づいた事例
【仮説】ある法律事務所が契約書レビューにChatGPT(GPT-5.4)を試したところ、 50ページを超える契約書を渡すとコンテキスト制限に引っかかり全文参照ができなかった。 1Mトークン対応のClaude Opus 4.6に切り替えたところ、 1回の処理で全文を参照しながらリスク箇所を特定できるようになった。 「全文を一度に渡す必要がある業務」はClaude有利、「短い問い合わせの大量処理」はGPT-5.4有利という境界が明確に存在する。
6. まとめ:2026年は「1つに絞る」より「使い分け」
Claude Opus 4.6とGPT-5.4はいずれも2026年の業務水準を十分満たすモデルだ。 「どちらが最強か」という問いは意味をなさなくなっている。 重要なのは「どの業務にどちらを当てるか」の設計であり、その判断基準は以下の3点に集約される。
-
判断1
長文・複雑推論が
必要か?
→ Claude -
判断2
マルチモーダル・
PC操作が
必要か?→ GPT-5.4 -
判断3
両方が
不確かなら
2〜4週PoC
図2:Claude vs ChatGPT 選定の3ステップ判断フロー
【仮説】2026年以降、API単価はさらに低下し「コスト差」という選定基準は薄まる可能性が高い。 それに伴い、選定の主軸は「どのモデルが自社の業務フローに深く統合できるか」という エコシステム適合性にシフトしていくと考えられる。 今は少額のPoCで両方を試し、自社に合った使い分けパターンを蓄積しておくことが先手になる。



